Trop de publications sérieuses ne sont pas traitées automatiquement par Zotero. Comment faire pour y remédier?
J’utilise Zotero de façon de plus en plus systématique pour conserver et organiser l’ensemble de mes lectures de recherche, de mes notes. Chacune de mes références bibliographiques est aussi liée à une version PDF de l’article ou de l’ouvrage. Si vous utilisez cette fonction vous avez remarqué que certains document PDF contiennent des métadonnées qui permettent de créer automatiquement une référence bibliographique en extrayant du fichier le type, le titre, l’auteur ou l’autrice, l’année de publication ou encore l’éditeur. Or, vous avez aussi remarqué que de nombreux PDF créés à partir d’un programme de traitement de texte ne contiennent pas ces métadonnées et qu’il faut par conséquent créer la référence manuellement.
Tout récemment, divers rapports ou études portant sur la découvrabilité et les métadonnées des secteurs culturels ont été publiés sous format PDF et à ma grande déception, ils ne contenaient paradoxalement pas de métadonnées de référencement. C’est quand même un peu navrant. Mais, bien honnêtement, je ne savais pas comment m’assurer que les métadonnées de mes publications PDF soient indexables automatiquement. Des recherches en ligne se sont montrées peu fructueuses pour résoudre ce problème. Je m’y suis donc attaqué.
Il semble, dans un premier temps, qu’il faille, pour créer un PDF indexable, avoir recours à la fonction OCR ou de reconnaissance optique des caractères de Adobe. Mais bon, la nouvelle version de Adobe Acrobat dans l’info-nuagique coûte $15 par mois. Ce n’est pas tout à fait abordable (pour ne pas dire Adorbable). Avant de m’y résigner, j’ai tenté de voir si un document Word importé dans Google Drive et ré-exporté en PDF jouissait du privilège de voir ses métadonnées crées par cette petite ruse. Sans succès. Plutôt que simplement produire un PDF en exportant sous ce format avec OpenOffice ou Word, ce qui, je le redis, ne produit pas un fichier indexable, je me suis dit que Adobe Reader DC en version gratuite permettait peut-être de résoudre la question. Mais bon, Reader en version gratuite ne permet pas de créer un PDF, il force la bascule en version payante.
J’ai ensuite fait un test dans la version payante de Microsoft Word dans Office 365 et sa fonction Fichier > Partager > Envoyer au format PDF puis Eureka! Les métadonnées du PDF ont été reconnues par Zotero. Par contre, la méthode de choix en matière de moissonnage des champs bibliographiques s’est montrée peu convaincante. Mon nom de famille a suivi mais mon prénom est devenu « Par ».
Ainsi, pour s’assurer de produire des PDF aux métadonnées indexables et reconnaissables par Zotero, il semble que nous devions donc utiliser des logiciels payants. Il faut soit s’abonner à Office 365, mais plus certainement à Acrobat Pro DC.
La méthode la plus sûre consiste à créer un PDF ou traiter un fichier textuel dans Acrobat avant de le publier et de le partager. Il faut réaliser une passe dans la fonction Numérisation et OCR puis sauvegarder. Cela a pour effet de transformer une image PDF en texte lisible et interprétable par les logiciels. Il faut ensuite ajuster manuellement les métadonnées sous Fichier > Propriétés du document > métadonnées supplémentaires et > avancées, avant de faire une nouvelle sauvegarde.
En conclusion, il me semble que cet effort est absolument nécessaire pour toute publication sérieuse, nommément lorsqu’elle traite de métadonnées et de découvrabilité.
Lorsque, à cause d’une crise sanitaire mondiale, toutes nos économies sont remises à plat, qu’attendons-nous pour réparer ce qui ne fonctionne pas ? Si vous reconnaissez le rôle fondamental de la culture et des métiers de la culture et que vous croyez qu’il faille enfin revoir le cadre et réduire la précarité du travail des créateurs et artistes, voici sept mesures très simples pour y arriver.
Micro-producteur/auto-producteur Les artistes sont parfois des salariés et parfois des travailleurs autonomes. Il ne faudrait pas les pénaliser pour cette situation et reconnaître ce double statut. Il faudrait éviter de les forcer à s’incorporer ou à mettre sous contrat d’autres artistes pour reconnaître leur statut de producteur. Il serait plus équitable de leur octroyer les aides à la production ou les crédits d’impôt sur la masse salariale, dès lors qu’ils investissent à risque dans l’élaboration d’un produit culturel.
Street musicians – National Galleries of Scotland
Statut de travailleur intermittent Tout comme les travailleurs saisonniers, il est important de permettre aux artistes d’avoir accès à des aides lorsque leurs heures travaillées ou leurs recettes sont insuffisantes pour assurer le minimum vital. Les périodes de travail des artistes sont irrégulières, il faut ainsi leur permettre de cumuler leurs heures, de souscrire à une caisse d’assurance chômage et d’avoir de l’aide lorsque des périodes de creux surviennent. Il est important de ne pas imposer de délai de carence pour toucher de l’aide. Comme pour une petite caisse, il vaudrait mieux attribuer cette aide dès le début de la période de cessation des activités, puis l’ajuster selon les revenus déclarés dans un rapport des recettes factuel.
Recensement national des productions Nous souhaitons de plus en plus promouvoir la présence d’un minimum de contenus nationaux et locaux dans nos émissions, sur nos ondes, sur Internet (pensons par exemple à #MusiqueBleue). Pour cela les artistes et les producteurs doivent absolument inscrire leurs produits culturels à un recensement national, sans quoi ils ne pourront bénéficier de ces mesures de contenus minimums et des recettes en découlant. Il est difficile, voir impossible de favoriser la consommation d’une proposition artistique en vertu de son territoire de production sans en faciliter cette qualification.
Transparence des identifiants Le dépôt au recensement prévu précédemment doit contenir les identifiants uniques ISO des artistes, créateurs, contributeurs, œuvres et productions et permettre l’émission d’un identifiant pérenne et transparent par les organismes de régulation industrielle. Les identifiants ISO qui sont associés à un produit culturel doivent être publiquement exposés et moissonnables sur Internet pour permettre la transparence des comptes et l’attribution appropriée des œuvres et produits à leurs créateurs et producteurs.
Redevance plancher Si l’on écoute 500 minutes de contenus en ligne tous les jours (c’est un peu plus de huit heures…) durant tout un mois sous forfait à $10, les recettes brutes pour chacune des pièces ou segments de 5 minutes devrait représenter autour de 30 sous /centimes (0,33). Une redevance de 10% versée à la chaîne des ayants droits de la création et de la production (0,03) représente un coût d’une matière première très accessible. Actuellement, il n’est pas rare que de tels segments génèrent moins du dixième, et parfois même du centième de cette somme. Il faut imposer une redevance plancher pour les contenus aux entreprises qui vendent ce type de services (*500 x 30 = 15000 / 5 = 3000 segments / 10$ ou 1000 centimes).
Droit de suite vidéo des interprètes S’il est généralement prévu pour les utilisateurs de contenus culturels de souscrire à une licence d’utilisation, il est curieux de constater qu’actuellement, les artistes interprètes, danseurs, comédiens, musiciens ne touchent aucun montant lorsque leur prestation, leur image, est rediffusée sur les chaînes de vidéo à la demande. Il est impératif de reconnaître qu’il s’agit là désormais de la méthode privilégiée d’accès à la culture et des régimes de gestion collective du droit de suite des interprètes doivent être mis en place.
Libérer les calendriers et les billetteries Celle-ci concerne les artistes et diffuseurs culturels eux-mêmes. Nos sociétés remettent actuellement en question les horaires de travail, l’emploi du temps. Il faut prôner la libéralisation des dates des saisons théâtrales, des heures de tenue des concerts pop. Pourquoi les galeries sont-elles fermées le dimanche, les spectacles débutent-ils à 22 heures et les théâtres fermés l’été? Qui a vraiment envie de sortir un mardi de février s’il est possible de le faire un vendredi de juillet et de choisir d’acheter son billet le soir même plutôt que six mois à l’avance?
Pour en lire davantage sur ces enjeux :
Bisaillon, J.-R. (2020, septembre). Fragilités structurelles des secteurs culturels dans un contexte de crise et de révision du statut de l’artiste. Regards de l’IEIM (Montréal).
Jean-Robert Bisaillon 20190101 – En 2019, le Ministère de la culture du Québec consentira de nouveaux efforts et budgets à mesurer la visibilité et stimuler le rayonnement des œuvres québécoises sur Internet. Il est possible de consulter le cadre de référence de ces mesures sur le site du Plan culturel numérique du Québec http://culturenumerique.mcc.gouv.qc.ca/pole-visibilite-et-rayonnement/
Faire cela est important, mais aussi très complexe. Nos décideurs publics en comprennent-ils toute la portée? Assumons que oui. Enfin.
En ce jour de lancement de médiumsaignant, j’ai décidé de revoir ces 6 motifs pour les porter à 10 et pour en faire ma résolution de 2019. Un tel chantier reflète on ne peut mieux l’importance de travailler collectivement, premier élément de la ligne éditoriale de médiumsaignant.media
Les
10 raisons d’état sont les suivantes :
Attribuer
les crédits aux artistes, ayants droits et contributeurs
Lier
artistes, ayants droits et contributeurs à des identifiants uniques
Inclure
un code géographique ou territorial
Adopter
les standards mondiaux DDEX
Siéger
sur les tables trans-nationales de définition des normes
Tracer
avec précision les usages des contenus
Arrimer
avec robustesse les fichiers binaires audio ou vidéo avec leurs
métadonnées
Développer
un référentiel commun et exposer les œuvres et leur documentation
sur les réseaux ouverts et liés
Améliorer
et mesurer la visibilité, le rayonnement, la découvrabilité des
contenus
Surveiller
le respect de seuils en matière d’offre minimale
Board Bullseye – Crédit photo : Christian Gidlöf (Domaine public)
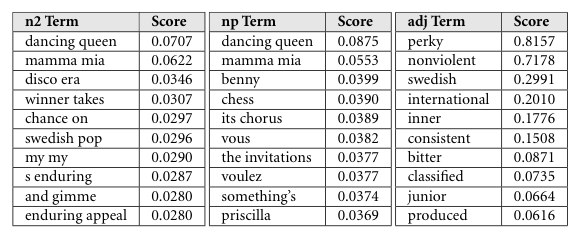
1. Attribuer les crédits aux ayants droits et contributeurs : une œuvre musicale enregistrée et numérisée est un code binaire orphelin qui ne dévoile rien de sa source et des ayants droits concernés si ces informations ne sont pas ajoutées aux fichiers audio ou ne sont pas liés aux bases de données corollaires. La compilation statistique des usages et la reddition de compte sont par conséquent faussées ou incomplètes.
Sont
visés les auteurs, compositeurs, éditeurs originaux, interprètes
et musiciens, producteurs initiaux, réalisateurs, studios
d’enregistrement, etc.. Les politiques publiques de soutien à la
production de contenus doivent inciter les bénéficiaires de mesures
financières à incorporer les noms des ayants droits, contributeurs,
ententes de répartition (Embedded
Metadata – Blockchain),
dans les conteneurs textuels des objets de propriété intellectuelle
numérisés. Voir aussi la raison 7.
25%
des contenus exploités par les plateformes de musique en-ligne ne
sont pas arrimés aux ayants droits concernés…1
2.
Toute œuvre de propriété intellectuelle ou contributeur à
celle-ci doit être
lié à un identifiant unique.
Les
codes ISRC, ISWC, IPI, ISTC, IPN, ISAN, EIDR, DOI, ISNI sont des
codes ISO ou industriels qui permettent aux machines et procédés
informatiques de tracer les contenus et de discerner les homonymes
(disambiguation).
Un
identifiant approprié pour chacune des composantes du contenu est ce
qui permet aux ordinateurs d’associer un enregistrement à l’oeuvre
qu’il contient, aux paroles de cette chanson et aux contributeurs qui
en sont les artisans et ayants droit, de renseigner numériquement
l’intégrité de cette chaîne de valeur.
3.
Les métadonnées doivent inclure
un code géographique ou territorial
pour tout objet de propriété intellectuelle ou contributeur de
l’œuvre. C’est là la seule méthode qui permette la classification
de l’origine des pays ou territoires de création et de production
des contenus. L’usage des identifiants ISO3166-1, ISO3166-2,
UN-LOCODE, GeoNames ou .kml (Keyhole Markup Language) sont
nécessaires pour cela.
4.
Les entreprises de production, de distribution et les usagers
commerciaux d’œuvres numériques doivent adopter
les standards mondiaux DDEX
d’échange
de données informatisé
(EDI) (DDEX Message
Suite Standards) qui
incorporent les métadonnées : RIN (Recording Information
Notification), ERN (Electronic Release Notification),
MLC
(Music
Licensing Companies), DSR (Digital Sales Reporting).
5.
Lorsque nécessaire ou possible, les associations et entreprises
canadiennes, les instances chargées de définir nos politiques
publiques doivent siéger
sur les tables trans-nationales de définition des normes
et standards du numérique (UNESCO, CISAC, ISO, DDEX, ACEI-ICANN,
NCUC, ISOC, ISNI, W3C-RDF, IETF).
6. Permettre de circonscrire le quoi, qui, où et comment des contenus québécois et MAPL. Il faut savoir tracer avec précision les usages des contenus. Si les outils techniques pourront sous peu nous permettre de compiler plus systématiquement les usages, un effort politique sera nécessaire pour accroitre la portée du dépôt légal dans les bibliothèques nationales, effectuer un recensement annuel rigoureux des produits mis à disposition des publics et certifier le territoire de production ou de fixation des œuvres.
7. Que l’on croit ou pas en la pertinence et à notre capacité d’arrimer avec robustesse les fichiers binaires audio ou vidéo avec leurs métadonnées, c’est là un geste vertueux qui sous-tend une grande partie des efforts de documentation de la culture en ligne. Des efforts en matière de tatouage et de chiffrement des contenus ont cours et leur succès sera déterminant.
8. Pour tirer profit des progrès de l’intelligence artificielle, assurer la présence et le remontée de nos contenus culturels dans le web des données et les recherches vocales assistées, nous devons développer un référentiel commun et exposer les œuvres et leur documentation sur les réseaux ouverts et liés. Ce chantier permettra de plus de valoriser l’information saisie par la foule, par nos pairs et divers écosystèmes ouvertes existants.
9. Rétablir la relation entre les créateurs et les usagers, améliorer et apprendre à mesurer la découvrabilité des contenus dans l’offre numérique via les outils de playlisting et de recommandation. Utiliser des contenus enrichis et renouer avec les informations descriptives perdues lors du passage au numérique. Créer des listes d’écoute et des contenus éditoriaux, partager ceux-ci.
10. Sans prétendre que les nouvelles pratiques de mise à disposition et d’écoute, la numérimorphose, la musimorphose, menacent notre souveraineté et la diversité culturelle, il faut que les organismes canadiens d’application de la réglementation puissent surveiller le respect de seuils en matière d’offre minimale. Et tant mieux si les pratiques citoyennes et les robots de recommandation s’avèrent soutenir une fréquentation pérenne de notre culture!
Jean-Robert Bisaillon 20181230 NOTE. Pour essayer de bien maîtriser les variables de la recommandation musicale, enjeu majeur de souveraineté culturelle, j’ai traduit en 2017 l’article classique de 2012 de Brian Withman – cofondateur de The Echo Nest, projet acquis par Spotify en mars 2014. Je le publie de nouveau en début 2019 sur médiumsaignant, après l’avoir relu et revu.
Lorsqu’un logiciel de recommandation musicale vous fait une proposition, avez-vous l’impression qu’un programme informatique inintelligent tente de vous forcer un contenu qui ne vous intéresse pas le moins du monde? C’est souvent l’impression que l’on a – un ordinateur qui comprend vos goûts musicaux peut-il être autre chose que le fruit de la bêtise postmoderne? – et dans les faits c’est souvent ce qui se produit.
À quoi peut bien servir l’information à l’effet que si l’on aime un album des Beatles, il est possible que nous en aimions cinq autres? Amazon ne fait ici rien de bon pour soutenir la découverte d’un artiste indépendant en émergence, ni pour nous proposer une expérience musicale à valeur ajoutée. On s’en tient à utiliser la statistique pour faire davantage de gains commerciaux. Heureusement, ce type de proposition est le drosophile de la recommandation, l’infopub télé de fin de nuit en matière de qualité de prescription musicale. Sans aucun doute, Amazon ne prétend-t-il à autre chose. Plus récemment, nous avons passablement évolué et il existe de nombreuses méthodes fondées sur les propriétés de la musique et sur les habitudes d’écoute de nos amis et connaissances, pour nous faire découvrir la musique en ligne. Nonobstant cela, je déteste encore croiser des exemples navrants comme celui évoqué plus haut. Je déteste encore plus constater qu’il existe des initiatives en matière de recommandation musicale qui n’ont pas à coeur les mélomanes. Je me fais un devoir d’améliorer ce type d’expérience et je compte passer ici en revue les paramètres qui font que la recommandation fonctionne ou non. Pour cela, je me fonderai sur des exemples liés à l’application que je connais la mieux et que vous utilisez déjà, même si c’est parfois à votre insu : The Echo Nest. Plus encore, je souhaite me pencher sur ce qu’il est possible d’en tirer dans le futur.
Avant
de me lancer dans ces explications, laissez-moi me présenter. Je
travaille sur les engins de recommandation et de forage musical
depuis 1999 tant sur un environnement académique
(http://alumni.media.mit.edu/~bwhitman)
qu’industriel. En 2005, j’ai co-fondé The Echo Nest avec Tristan
Jehan. Aujourd’hui nos applications fondées sur divers algorithmes
forts intéressants dérivés de nos essais universitaires et le
travail soutenu de nos 50 employés à Boston, San Francisco,
New-York ainsi que Londres, alimentent les découvertes de la plupart
des services de musique en-ligne. Nous sommes actuellement survoltés
– ayant annoncé au cours de la plus récente année des
collaborations avec
eMusic, Twitter, EMI, iHeartRadio, Rdio, Spotify, VEVO et Nokia –
de nouvelles annonces étant imminentes – le tout s’ajoutant à nos
clients actuels MTV, MOG et la BBC. De plus notre API
(http://developer.echonest.com/)
a permis à des dizaines de milliers de développeurs indépendants
de créer des applications pour Discovr, KCRW, Muzine, Raditaz,
Swarm, SpotON et une centaine d’autres. Nous avions jusqu’ici été
une entreprise plutôt discrète, mais avec toutes ces nouvelles,
vient une certaine confusion quant à nos services et à la place que
nous occupons à l’égard des approches concurrentes. La presse a
tendance à nous coller une approche “machine” qu’elle juxtapose
à la démarche dite “humaine” de Pandora, l’acteur
complémentaire en ces matières. Cette réduction de la
problématique est plutôt injuste. En effet, comme tout le monde,
nous utilisons des programmes informatiques pour traiter des
montagnes de données musicales, et nous ne négligeons pas davantage
l’approche humaine que nos concurrents.
J’aborderai
des concepts technologiques tels le filtrage collaboratif, la
recommandation fondée sur les contenus qualitatifs (content-based)
ainsi que les approches manuelles utilisées par Pandora et All Music
Guide (Rovi). Je démontrerai que peu importe l’approche informatique
mise en oeuvre, ce sont les sources de données – comment elle
permettent de connaître la musique – qui constituent le
patrimoine sur lequel se fonde tout service de découverte musicale
fiable.
Qu’est-ce
que la recommandation? En quoi est-elle utile?
Les
musiciens sont de millions à tenter de s’imposer auprès des
auditoires et de se démarquer les uns des autres. De nos jours, il
est possible d’avoir gratuitement accès à près de 15 millions de
chansons – ce n’est pas la faute des auditeurs s’ils négligent une
proposition qui pourrait les renverser. Pour un musicien qui comme
moi est devenu informaticien (comme c’est aussi le cas pour de
nombreux de mes collègues) – il s’agit de la théorie à variable
cachée ultime. Si un engin intelligent permettait de prédire le
mariage parfait entre un musicien et un mélomane, les deux vis-à-vis
seraient gagnants. Or, la musique est fascinante, elle est constituée
d’une multitude de données et la problématique est encore loin
d’être résolue… Quiconque est actif dans le domaine des
technologies et de la musique se doit de manifester du respect pour
le champ de la découverte musicale assistée : il ne s’agit pas
d’une question de revenus des ayants droit, il ne s’agit pas de
technologies à l’état pur, il ne s’agit pas de statistiques de
clics, d’heures d’écoute ou de facteurs de conversion des
internautes. Au delà de ces considérations, les récentes années
ont démontré à quel point les divers filtres et guides sont
devenus vitaux pour que la musique elle-même existe et co-existe
dans les environnements numériques, pour que nous y ayons accès.
Nous enregistrons désormais des données pour plus de 2 millions
d’artistes et estimons qu’ils sont davantage au nombre de 50
millions, pour la plupart actifs. Tous méritent la chance d’être
entendus. Si nous pouvons nous moquer d’Amazon lorsqu’il nous suggère
un CD de Norah Jones après avoir acheté une souffleuse à neige, il
en est tout autre lorsque Pandora passionne des millions d’auditeurs
qui y découvrent un nouvel artiste. Les technologies de
recommandation alimentent les nouvelles formes de radiodiffusion et
la chance nous est donnée d’en faire un outil de valorisation pour
davantage que la courte tête du top 5% des artistes.
Lorsque
les gens évoquent la recommandation et la découverte musicale ils
veulent habituellement parler de l’une des ces quelques variantes :
Similitude des artistes ou des pièces musicales : une liste anonyme de propositions semblables à votre requête. Répandu chez presque la totalité des services de musique en ligne. Pas d’éléments de contextualisation, que des similitudes avec les artistes ou chansons que nous cherchions. Dans les faits, s’il ne s’agit d’une recommandation dans la mesure où les listes générées sont le résultat d’une requête de départ par l’usager (telle une recherche en ligne basique), il ne s’agit pas d’un modèle usager automatisé, ce que nous appellerions alors véritablement une recommandation.
Recommandation
personnalisée : fondée sur un profil usager spécifique (le
vôtre – vos écoutes, vos sauts, vos niveaux d’appréciation ou
vos achats), une liste de pièces que vous ne connaissez probablement
pas mais qui correspondent à vos habitudes.
Liste d’écoute créées
automatiquement (intelligente) : Les clients des services de
découverte musicale en ligne font appel à diverses formes de
création automatisée de listes d’écoute. Ce service se distingue
des approches mentionnées ci-haut, dans la mesure où l’on reçoit
une liste séquentielle de titres. Ces listes peuvent être
personnalisées (à partir de votre profil) ou non, générées à
partir de votre librairie musicale (par ex. iTunes Genius et Google
Instant Mix) ou non (Pandora, Spotify, Rdio ou encore iHeartRadio.)
Les listes ainsi générées devraient évoluer et pour plusieurs
cette évolution est fonction d’indications de l’usager (sauts,
j’aime etc.).
La
découvertes chez divers services populaires…
Personalisées
Anonymes
Listes
d’écoute
Pandora
Rdio
Suggestions
Amazon
All
Music Guide
J’évoquais trois
approches très différentes de proposer la découverte, mais
qu’importe celles-ci, il s’agit essentiellement d’applications qui
reposent sur un même noyau de données. Par exemple chez The Echo
Nest, nous tâchons de construire des listes de lecture émulant
l’expérience de la radiodiffusion et reposant sur nos observations
statistiques, les propriétés acoustiques, le contrôle de la
qualité – nos trois API – API basée sur les similitudes, API de
profilage des goûts (recommandations personnalisées) et API de
production de listes d’écoute, sont créées à partir de la même
base de connaissances compilées par nos analyses des propriétés
qualitatives acoustiques de la musique et de nos travaux d’analyse
sémantique.
Ces applications sont significatives pour les auditeurs. Les gens aiment les liste d’écoute et les flux analogues à la radiodiffusion, qu’importe si les données à la base d’expériences d’écoute, tout comme les ennuyantes listes d’écoute textuelles sont essentiellement fondées sur les mêmes références. Un des plaisirs de travailler chez The Echo Nest est de découvrir les usages qui se créent avec ces références, par la communauté, en matière d’interfaces et expériences usager. Les usagers veulent de la musique, que cette expérience soit ludique tout en reposant sur un service fondé sur un niveau de confiance optimal. Suivant cette logique, un service comme Pandora ne perdrait rien de ses actuelles qualités s’il était alimenté par The Echo Nest et gagnerait par ailleurs sur le plan de la profondeur de son échelle en matière de découvertes. Ceci constituerait une bonification de l’expérience. Compte tenu de la démonstration que nous avons fait de notre capacité à optimiser le recours aux données, il est moins important de parler de tels services que de leur véritable connaissance fine de la musique mise au profit des auditeurs – qu’importe comment ils ont été en mesure d’associer deux artistes obscurs tels Kreayshawn et Uffie. Nous laissons ces considérations aux blogueurs musicaux.
Voici ce que mes
observations savantes déduisent (je n’en sais rien avec certitude
sauf pour The Echo Nest) quant aux méthodes de constitution des
données des services de recommandation :
Sur
quelles approches les services les plus populaires fondent-ils leurs
recommandations?
Historique des achats
et données d’activité sur iTunes2
Echo
Nest
Analyses acoustiques
et analyses sémantiques
Bien qu’il existe plusieurs autres services de découverte musicale, cette liste couvre le spectre entier des approches. La plupart des services que vous utilisez utilisent soit ces plateformes en direct (Last.fm, Echo Nest, AMG all license data ou encore en accédant aux données de celles-ci via les API) ou utilisent des approches suffisamment similaires pour ne pas justifier que nous les approfondissions davantage.
Nous pouvons extraire de cette liste un nombre plutôt restreint de méthodes déterminantes en matière de constitution de données : (1) Données d’activité (activity data), (2) Contenus éditoriaux, (3) Analyses acoustiques et (4) Analyses sémantiques.
Les
deux premières catégories ont des noms plutôt descriptifs : il
est possible d’en apprendre sur la musique par les activités qu’elle
génère – les écoutes, les achats, les votes d’appréciation –
Kreayshawn et Uffie sont considérés similaires puisque les mêmes
personnes achètent leurs simples ou leurs donnent des notes élevées;
il est aussi possible de connaître la musique par la lectures de
critiques, de textes et chroniques spécialisées. Par ailleurs, il
est assez récent que des bases de données servent à stocker des
activités d’écoute ou autre, générées par filtrage collaboratif,
moissonnage des préférences en matière de goût et notes
appréciatives compilées par sondage ou saisies par l’usager.
Les
deux catégories suivantes, soit les analyses acoustiques et
sémantiques, ont été développées par les praticiens de notre
industrie en réponse aux insuccès des résultats générés par les
premières. Je les aborderai plus en détail puisque ce sont celles
qui créent la magie propre à Echo Nest.
Souci
et échelle
Dès
le départ, les principes à la base de l’approche de découverte
Echo Nest sont “le
souci et l’échelle.” Lorsque Tristan et moi avons
démarré la société en 2005, nous étions deux nouveaux docteurs
en analyse musicale munis d’idées pas vilaines du tout sur le plan
technologique. Tristan davantage dans le champ de l’analyse
acoustique (soit un ordinateur qui génère du sens à partir d’un
signal audio) et moi qui maîtrise le moissonnage de données et
l’analyse langagière (ce que les gens disent et font de la musique
et ce que nous pouvons en tirer). Nous avions sondé l’offre en
matière de découverte musicale assistée pour nous apercevoir
qu’essentiellement chacune souffrait d’un manque de souci du détail
ou de la faiblesse de l’échelle des données qui l’alimentait –
parfois et souvent des deux lacunes. Notre motivation à mettre en
oeuvre une »startup », alors que nous n’en avions pas le profil,
découle de notre sentiment de pouvoir résoudre ensemble cette
problématique.
Souci
: « est-ce utile pour le musicien ou l’auditeur » – Échelle : «
Savons tout ce qu’il faut savoir »
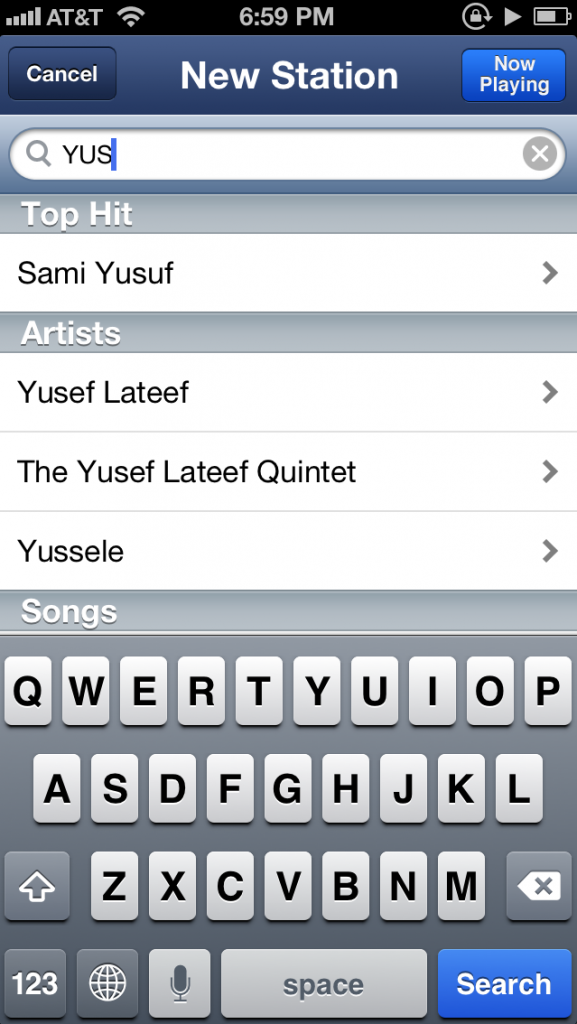
La notion de taille d’échelle est facile à expliquer : il vous faut connaître au maximum la musique afin de faire des recommandations justes. Si vous ne connaissez pas un artiste en émergence, vous ne pouvez le recommander. Si vous analysez, notez ou comprenez uniquement les offres les plus populaires et évidentes vous commettrez une erreur systémique. Par essence les approches de recommandation entretenues manuellement ne parviennent pas à atteindre un taille d’échelle significative. Nous suivons l’activité de plus de 2 millions d’artistes et 30 millions de chansons et il serait impossible pour un service rédactionnel de maintenir une veille sur autant de données possibles. Même les plateformes entretenues par les bénévoles ou la communauté ne peuvent compter sur des ressources suffisantes – il n’y a que 130 000 pages artistes dans Wkipedia et Pandora vient tout juste de croiser le seuil du million d’artistes après 10 ans d’efforts. Si vous tentez de trouver un nouvel artiste sur Pandora vous obtiendrez fatalement :
Pandora affiche ici la faiblesse de son échelle. Il s’écoulera longtemps avant que la plateforme n’obtienne d’informations sur YUS (http://soundcloud.com/yusyusyus/nowadays) et peut ne jamais en obtenir si l’artiste vends peu. C’est là une mauvais nouvelle qui pourrait vous mettre en colère : pourquoi laisseriez-vous une tierce partie agir tel un filtre culturel sur votre propre expérience de la musique? Pourquoi utiliseriez-vous un service de découvertes qui vous »cache » des informations?
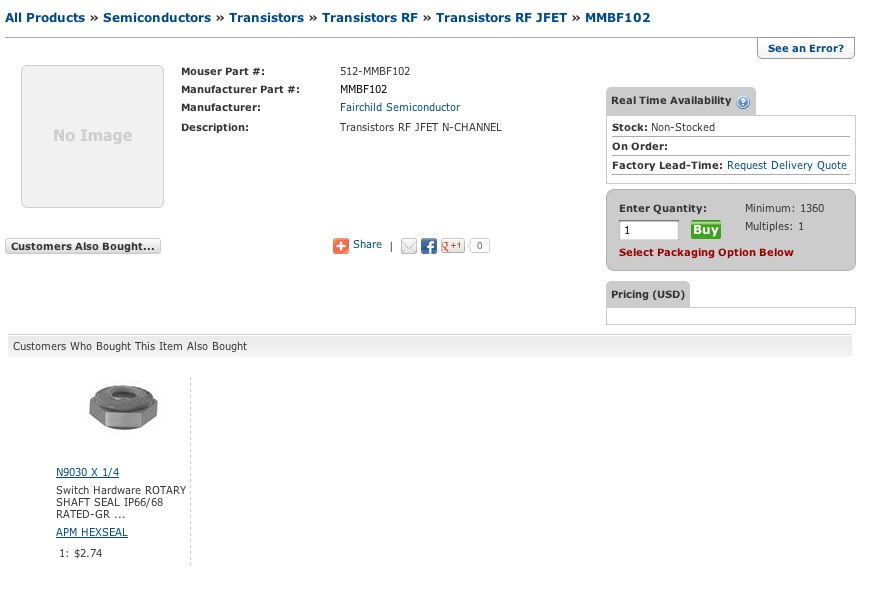
Les approches fondées sur les données d’activité ( Last.fm, Amazon et iTunes Genius) souffrent elles aussi d’un problème de taille d’échelle qui se manifestent un peu différemment. Il devient souvent trivial ou impertinent de charger une base de données de titres musicaux dans un environnement destiné à produire des recommandations automatiques fondées sur des données d’activité (tel le filtrage collaboratif ou la production folksonomique). Je me suis fréquemment attaqué à la naïveté de telles méthodes. Si un service de musique en ligne dispose de données d’activité (par exemple l’utilisateur A a acheté/écouté la pièce Y au moment Z), ses ingénieurs seront systématiquement tentés d’activer les fonctions de recommandation qu’importe s’il en résulte des résultats de mauvaise qualité. Il semble exister une facilité contradictoire à ne pas se soucier de faire de mauvaises recommandations. Il en fut de même lorsque je tentai récemment d’acheter un transistor dans une boutique en ligne :
Outre faire des recommandations impertinentes, ces approches souffrent souvent de biais culturels fondés sur la popularité où de nombreuses propositions ne génèrent simplement pas assez de données d’activité pour donner au système d’automation la chance de produire un résultat de correspondance. Ces systèmes ne peuvent faire mieux que ce que leurs utilisateurs ont bien voulu leur dire et par conséquent de nombreuses propositions musicales moins populaires éprouvent d’énormes difficultés à se démarquer.
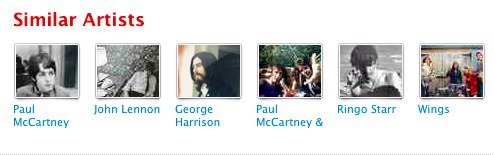
Le souci du détail est quant à lui un concept plus difficile à cerner et nous lui avons dédié beaucoup d’efforts pour le définir et l’encoder dans nos produits. Je traduirai ce concept par un simple questionnement : est-ce utile pour le musicien ou l’auditeur? Un examen de passage efficace pour vérifier une recommandation d’artiste ou de chanson similaire consiste à utiliser les Beatles. Ne s’agira-t-il que de projets solos des membres du groupe? Pour la plupart des services voici ce qu’on l’on obtient en effet :
On a ainsi affaire à un résultat exact sur le plan statistique, mais d’aucun intérêt en matière de découverte musicale3.
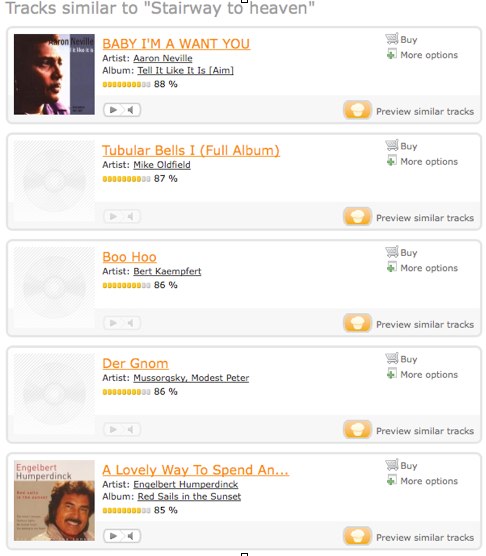
Les données d’activité peuvent nous en dire énormément sur les habitudes d’écoute, mais ne pas être utiles en matière de découvertes. Utilisées comme nous venons de le voir, elles trahissent un grand manque de souci du détail de la part du service de recommandation. Le souci est présent dans les approches sociales, manuelles, éditoriales car les humains y excellent. Mais lorsque nous utilisons des méthodes automatiques d’analyse statistique ou de signal audio afin de générer une meilleure amplitude d’échelle, il faut aussi y manufacturer un certain souci du détail. Les approches purement automatiques (tel l’exemple tiré de Mufin qui suit) sont médiocres sur le plan du souci du détail et de la qualité :
Le souci du détail constitue une couche additionnelle d’assurance de qualité qui doit venir s’appliquer sur toutes les approches automatiques. Vous devez pouvoir assumer les résultats que vous proposez et en résoudre les failles dès qu’elles ne sont plus utiles aux musiciens ou aux auditeurs. Votre score de médiocrité (What the F… WTF ) (http://musicmachinery.com/2011/05/14/how-good-is-googles-instant-mix/) doit être le plus bas possible! Nous consacrons beaucoup d’efforts à inscrire les valeurs du souci dans nos produits et aimons généralement les résultats qu’il produisent :
Un environnement qui ne respecte pas les notion de souci et d’échelle ne peut se mériter la confiance des auditeurs et l’assurance d’être utile pour les musiciens. Il échoue auprès des deux publics qui lui donnent sa raison même d’exister.
J’ai débuté mes travaux d’analyse musicale en 1999 au NEC Research Institute de Princeton au New Jersey (je suis parvenu à force d’astuces et pressions à y obtenir un stage puis un emploi permanent). Le NEC regroupe alors la crème des scientifiques engagés dans les recherches sur le forage de données, les fouilles sémantiques, l’apprentissage automatique et le traitement automatique du langage naturel (NLP4).
J’étais là à me chercher après avoir abruptement quitté mon programme de doctorat en NLP à l’Université Columbia. J’étais aussi un musicien et donnait plusieurs concerts dont un certain nombre dans des entrepôts abandonnés et des bars “bruns”, endroit où 20 clients pouvaient se présenter et que seulement la moitié savait qui vous étiez. Il y avait à ce moment là un réel engouement pour “the future of music” – bien davantage qu’en ce moment, car nous sentions que les forces positives vaincraient et rapidement. Lorsque je me suis connecté la toute première fois sur Napster avec ma ligne DSL je me suis régalé de constater que pour la première fois je pouvais télécharger une chanson en moins de temps qu’il ne fallait pour l’écouter. C’était le point de bascule pour l’accès à la musique, mais peut-être aussi un important recul pour la découverte. Nous étions coincés avec ce genre de résultats :
La recherche nécessaire est abyssale : recherche sur des tags ID3v1 (contenant un maigre 32 caractères pour chaque rubrique artiste, titre, album, un seul octet pour le genre)(http://notes.variogr.am/post/225922016/armed-forces-in-alphabetical-order-archive), sur un nom de fichier obscur (“C:\MUSIC\MYAWES~1\RAPSONG.MP3”), impossible de faire des recherches sinon en fouillant les disques durs d’autres usagers. Bien que je rende ma musique disponible, personne ne la télécharge puisqu’il est impossible pour le public de la découvrir. Un ami obtient davantage de résultats en falsifiant le nom de ses fichiers pour leur ajouter la mention remixage par APHEX TWIN…
J’étais abonné à plusieurs listes de distribution, groupes USENET, lecteur d’un nouveau truc qu’on appelle “weblog” et de sites d’actualités musicales. Pour moi, si l’écoute musicale est une pratique très privée (souvent dans des écouteurs bien étanches), sa découverte est très sociale. Rapidement, je me suis dit qu’il devait y avoir une façon de tirer profit de toutes ces conversations entourant la musique – pourvu qu’il soit possible d’en automatiser la procédure. Est-il possible pour un ordinateur de lire tous ces articles? Si un mélomane parlait de ma musique dans un recoin du Web, le système devait le savoir!
Taille d’échelle et souci : des personnes en chair et en os qui alimentent un système automatisé de grande taille qui ne requiert pas de manipulation humaine, de remplir un sondage, de créer un profil sur un réseau socionumérique. Après près de dix ans de forage de données, de recherches sur la musique et le langage (d’abord à NECI, puis en préparant mon doctorat au Media Lab du MIT) The Echo Nest est présentement le seul service d’analyse musicale à adopter cette approche. Notre approche fonctionne. Nous fouillons le Web en permanence, répertoriant le contenu de plus de 10 millions de pages liées à la musique par jour. Nous utilisons des méthodes de filtrage afin de soustraire les contenus inappropriés de nos résultats, nous sommes en quête des noms d’artistes dans de volumineuses masses de contenus sémantiques (http://notes.variogr.am/post/6687194793/the-echo-nest-puddle-and-artist-entity-extraction) et tamisons le texte autour de ces résultats. Tous les termes associés à la musique que quiconque utilise en ligne est moissonné par nos systèmes qui, à la recherche de termes descriptifs, noms, mots que nous nommons »vecteurs culturels » et »termes phares » (top terms), les classent dans des conteneurs. Chaque artiste, ses oeuvres et enregistrements, possèdent ses termes phares qui évoluent quotidiennement. Ces termes sont associés à des valeurs de pondération qui nous indiquent les probabilités de les voir associés à des descriptions musicales.
Nous n’utilisons pas de vocabulaire contrôlé et sommes en mesure d’assimiler les nouveaux termes musicaux aussi rapidement qu’ils apparaissent. Nos systèmes fonctionnent avec plusieurs langues latines de nombreuses cultures. En plus de ce travail statistique autour de procédés de traitement automatique du langage naturel, nous utilisons des données structurées par un nombre important de partenaires et de sites communautaires aux données accessibles tels Wikipedia et MusicBrainz.
Nous appliquons semblables approches rigoureuses et vectorielles (vecteurs culturels) aux bases de connaissances structurées : si Wikipedia indique que le lieu de résidence d’un artiste est NYC, sa maison de disques est basée à New-York, NY et que sa page Facebook indique la mention “EVERYWHERE ON TOUR 2012”, il nous faut savoir quelle information retenir aux fins d’indexation. Souvent, les données ou vecteurs culturels des bases structurées sont la résultante d’une synthèse de plusieurs sources de données différentes. Lorsqu’une requête est traitée par notre système et ayant pour objectif de proposer un artiste similaire ou une liste d’écoute pertinente, nous utilisons les vecteurs culturels de l’artiste ou la pièce source pour générer les correspondances en temps réel. Ceci n’est pas simple à réaliser dans une base de grande échelle, mais au cours des années, nous sommes parvenus à effectuer suffisamment de réduction de données massives (big data parsing) pour permettre une gestion efficiente des requêtes. Nous ne conservons pas ces données et correspondances en mémoire cache parce que les paramètres évoluent constamment – la conversation qui a cours autour de la musique est très capricieuse et le son d’un artiste peut se transformer du jour au lendemain.
Quantité de données utiles ne relèvent pas d’une analyse culturelle de la musique : le volume de conversations est plutôt utile pour nous renseigner sur la notoriété circonstancielle, temporelle d’un artiste. Nous utilisons anonymement les contenus textuels que nous recensons au titre de données d’auditoires sans devoir dépendre de données provenant de service d’écoute en ligne. Nous archivons enfin une documentation liées aux artistes et aux enregistrements puisqu’elle représente une valeur confirmée pour nos clients – notamment en mode recherche ou fil d’actualité (feed) – nous proposons des critiques, de la nouvelle.
Internet n’est pas La Bibliothèque de Babel que nous croyons être et souvent les musiciens moins populaires sont négligés par les »univers culturels » que nous fréquentons. De plus, les descriptions des univers musicaux négligent souvent les éléments qui décrivent véritablement la musique pour privilégier les potins, l’angle de la célébrité, données certes pertinentes, mais loin de constituer les seules sources utiles. Cette problématique est fort bien illustrée par une recherche Google sur Rihanna (https://www.google.com/search?q=rihanna&oq=Rihanna&aqs=chrome.0.69i59j0l5.2375j0j9&sourceid=chrome&ie=UTF-8). Enfin, l’activité en ligne se concentre en majeure partie sur les artistes alors que les chansons sont négligées – malgré quelques discussions sur les enregistrements et les oeuvres. Ces divers enjeux (tout comme la logique du bon sens) nous obligent à nous questionner sur notre capacité de décrire à la fois le son d’un enregistrement et la représentation que se font les auditeurs de son interprète et de l’oeuvre. Si nous voulons faire tout cela avec un souci de qualité et selon une échelle significative, nous devons le faire en usant de procédés automatisés et d’ordinateurs assumant une écoute attentive.
Un ordinateur peut-il véritablement écouter de la musique? Plusieurs affirment cela depuis longtemps, mais personnellement je n’ai jamais entendu une liste de recommandation entièrement automatisée, fondée strictement sur l’analyse acoustique qui soit convaincante – j’ai tout exploré, lu toutes les études scientifiques, testé les projets des »start-ups », ceux des grandes corporations et notre propre technologie. Ces enjeux sont liés aux attentes des auditeurs. Les ordinateurs sont doués et rapides pour exécuter certaines tâches telles déterminer le tempo, la tonalité, l’amplitude sonore. Ils le sont moins pour d’autres tâches, jusqu’à ce que la technologie évolue : détecter la signature rythmique, transcrire une mélodie dominante ou identifier le timbre d’instruments spécifiques. Mais même si un ordinateur parvenait à effectuer toutes ces tâches, est-ce que ces informations se traduiraient par de meilleures recommandations? Probablement pas. Avec le temps, nous avons fait la démonstration que les attentes des gens à l’égard de facteurs telles la »similitude » – tant pour une liste d’écoute, qu’une liste d’artistes ou de pièces – sont teintées d’un fort déterminisme culturel qu’aucun ordinateur ne peut déduire seul se fondant sur l’analyse d’un signal audio.
Cela
dit, l’analyse acoustique joue malgré tout un rôle majeur dans la
conception de nos algorithmes. Les auditeurs s’attendent des listes
d’écoute qu’elles offrent des transitions souples et agréables. Une
pièce calme ne doit pas être suivie d’un »riff » métal extrême
(sauf si c’est ce que l’auditeur a délibérément demandé). Pour
les activités sportives, le tempo devrait s’accélérer
progressivement. Une liste bien mixée devrait conserver des
arrangements relativement homogènes. Les pièces doivent s’imbriquer
les unes dans les autres comme si un DJ était aux commandes,
conserver un tempo stable et des tonalités harmoniques.
Finalement,
tous ces paramètres et considérations posent des questionnements au
niveau de l’interface usager. Est-ce qu’on veut avoir affaire à une
»interface de recherche super débile » où un auditeur pourra
effectuer une requête par tonalité ou encore dynamique de
l’amplitude sonore? Un de nos premiers produits conçus par Tristan
proposait un bouton qui permettait de répéter un segment de chanson
en boucle (voir
un remix automatisé de 10 minutes d’une pièce de
Phoenix)(http://dl.dropbox.com/u/394242/mp3s/phoenix_10.mp3)
– ce bouton est devenu plus tard le »Paul’s amazing Infinite
Jukebox » (http://infinitejuke.com/)
–
ce type d’expérience fascine les chercheurs qui se penchent sur de
nouvelles approches d’écoute musicale qui pourraient un jour devenir
plus importantes que la notion même de découverte assistée.
The
Echo Nest audio analysis engine (PDF
–
http://docs.echonest.com.s3-website-us-east-1.amazonaws.com/_static/AnalyzeDocumentation.pdf)
contient une série de processus d’écoute informatisés qui
permettent des interactions de faibles niveaux (par exemple le moment
où débute chaque premier temps d’une mesure) ou de niveaux élevés
(telle les qualités dansantes) de n’importe quelle pièce de musique
au monde. Nous analysons toute la musique qui nous est soumise et les
développeurs tiers peuvent soumettre leurs propres contenus audio à
nos API afin de constater tout ce que nous générons comme
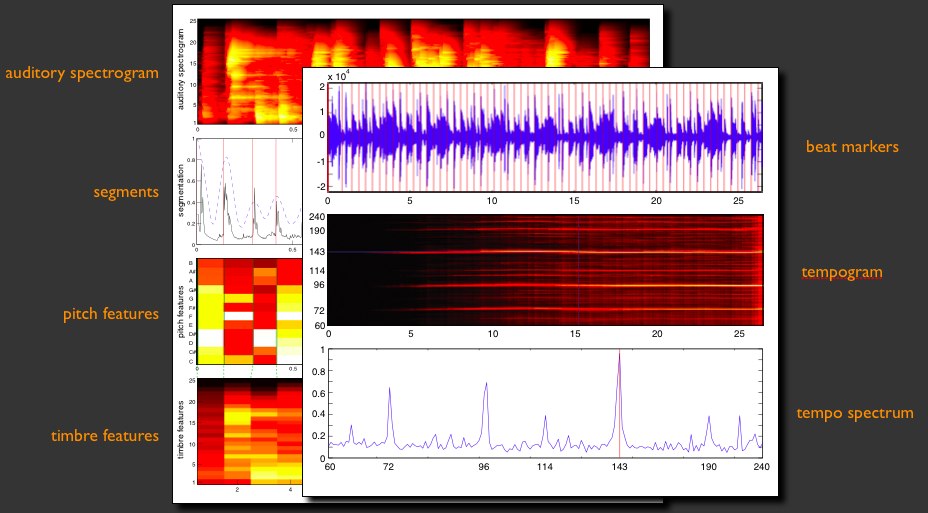
information sur ceux-ci. Nous débutons nos processus d’analyse par
émuler l’oreille et modelons les paramètres de fréquence et
amplitude selon une approche perceptuelle similaire à celle employée
par les codecs de numérisation comme le MP3 et e AAC. Par la suite,
nous segmentons l’audio en multiple parcelles – de 200
mili-secondes à 4 secondes – pour refléter l’activité de la
pièce. Pour chacun des segments il nous est possible de dire la
tonalité (selon la gamme chromatique de 12 tons/vecteurs que nous
appelons chroma),
le volume (ou amplitude, selon un modèle ADSR –
Attack/Decay/Envelope/Sustain), puis le timbre selon un nouveau
modèle vectoriel à 12 facteurs (dimensions) qui nous renseigne sur
la nature du son, la présence de divers instruments, la saturation
etc. Ensuite nous documentons le tempo par subdivisions (VU
métriques) que nous nommons tatums,
que nous appliquons aux mesures et à la structure des pièces, que
nous nommons selon les pratiques de la composition soit intro,
couplet, refrain, pont. Ces informations de faible niveau sont
ensuite bonifiées par des applications d’apprentissage machine et
d’intelligence artificielle que Tristan et son équipe ont conçues
au fil des années et qui permettent une compréhension des chansons
d’un niveau supérieur. Nous statuons sur des attributs associés aux
chansons tels la »dansabilité », l’énergie, la tonalité, la
vivacité, la teneur en contenus vocaux qui nous permettent d’établir
la nature de chaque chanson en lien avec des repères flottants
placés sur celles-ci. Ces attributs sont à nouveau dérivés
d’observations effectuées sur de larges bancs de tests heuristiques
et statistiques : nous travaillons avec des musiciens et avec leur
expertise à évaluer nos modèles à l’aide véritables données
audio corroborées par ces derniers. Nos analyses audio peuvent être
comparées à des partitions informatiques en mesure de témoigner de
la vitesse, de progressions du volume sonore, de la présence
d’instruments spécifiques. Les données générées par nos analyses
sont à ce point granulaires qu’il est possible de les utiliser pour
générer des remixages
automatisés
(http://echonest.github.com/remix)
dont les coupes sont impossibles à repérer pour l’auditeur5.
Nous
n’utilisons jamais un seul type de données d’analyse pour effectuer
nos recommandations. Nous juxtaposons toujours nos données
culturelles et nos analyses acoustiques du signal pour trier les
résultats. Il est particulièrement révélateur de tester les
engins de recommandation avec des ballades de groupes heavy métal –
nous nous attendrons à obtenir d’autres ballades par des groupes
heavy métal. Pour y parvenir il est essentiel de combiner les
analyses culturelles et acoustiques. Les informations acoustiques
seront déterminantes pour conserver l’ambiance et la cohérence de
la liste d’écoute recommandée.
Quoi encore…
Je le répète, j’ai testé toutes les approches de recommandation automatisées, les technologies et les services en ligne. C’est mon travail. J’ai été étonné de constater les progrès et le développement de la maturité des approches tant en recherche académique que dans l’offre commerciale. Nous avons fait un long parcours depuis RINGO (http://jolomo.net/ringo.html) et bien que l’approche Echo Nest se démarque sur le plan de la qualité brute de ses résultats, nous avons encore beaucoup de chemin à parcourir. Deux courants émergents qui se profilent à l’horizon auront tôt fait d’enflammer l’univers des propositions actuellement disponibles :
Les approches sociales de découvertes de mes applications musicales favorites This is my jam (http://thisismyjam.com/) et Swarm.fm (http://swarm.fm/), les alertes d’activité musicale de nos amis Facebook et la diffusion en temps réel de services comme Turntable.fm ne proposent pourtant pas de recommandations automatisées. Les recommandations musicales des amis selon les dynamiques F2F (Friend-to-friend) que permettent les réseaux socionumériques sont extrêmement riches pour la découverte (et j’y recours fréquemment). Par contre ce ne sont pas des moteurs automatisés et ces approches ont peu de chance de prédire les attentes, ils échouent souvent en matière de taille d’échelle pour permettre les découvertes véritablement inattendues.
Même si ce n’est pas l’objet de cet article, il ne faut pas négliger la puissance de la recommandation sociale. Il existe une dimension très séduisante et personnelle dans ces approches : beaucoup de gens n’aiment pas l’idée qu’un ordinateur leur dicte quoi faire. Il existe de nouveaux services qui mélangent habilement les deux approches. L’option des »related jams » du service This is my jam en est un, tout comme les nouvelles options “Discover” (http://www.spotify.com/us/blog/archives/2012/12/06/discover/) de Spotify. Les recommandations pourraient devenir des facteurs d’enrichissement de votre vie sociale en ligne : il n’est pas dit que si vos amis n’ont pas encore repéré FranOcean que des signaux ne sont pas observables à l’effet qu’ils le feront sous peu, le filtrage social nous y mène. Le fait que ces propositions puissent émaner de vos amis a beaucoup plus de valeur que lorsqu’un système automatisé vous recommande une »liste d’artistes que vous pourriez aimer ».
L’intelligence des
auditeurs
Quand écoutez-vous de la musique? Est-ce le matin en vous rendant au travail? Les fins de semaine en vous reposant à la maison? Lorsque vous le faite, est-ce que vous privilégiez des albums complets, les pièces individuelles d’une liste compilée? Est-ce que vous syntonisez aléatoirement une station automatisée ou écoutez-vous vos propres compilations? S’il pleut ou neige, risquez-vous de modifier vos choix? L’élément le plus déstabilisant de cette quête pour la recommandation parfaite et ce qui est aussi vrai pour notre propre système, c’est qu’aucune approche ne tient compte de cette dimension contextuelle de l’auditeur. Beaucoup de projets se développent en ce sens, tant chez nous et que nous ne pouvons encore dévoiler, que chez Spotify ou Facebook. Nous consacrons d’importantes ressources à notre projet »taste profile » (http://developer.echonest.com/raw_tutorials/catalog_api/what.html) – l’API qui dévoile l’activité musicale sur nos serveurs et qui une forme de scrobble 2.0 (http://en.wiktionary.org/wiki/scrobble) et qui présente à la fois l’activité d’écoute et nécessairement certains éléments de contexte qui l’entoure : vos patterns de comportement, vos collections musicales, vos écoutes agrégés sur plusieurs services différents et possiblement sur des domaines (URL) spécifiques.
Nous publions désormais des API qui permettent l’analyse d’activités globalisées (http://blog.echonest.com/post/33229165293/taste-profiles-go-public) afin de faire apparaître des phénomènes de popularité, de modes provisoires. Il s’agit de bien plus qu’un simple forage d’activité faisant appel au filtrage collaboratif : nous devrions parvenir à comprendre les motivations de l’auditeur au delà de simplement profiler ses goûts en nous basant sur ses achats et ses activités d’écoute en ligne. Comprendre complètement la musique et l’auditeur auquel elle est destinée – l’ultime frontière de la recommandation.
1
Je sais qu’il font de l’analyse acoustique, mais ne sais pas à quel
point ils en font usage pour les flux radio et les recommandation
d’artistes similaires
2
Ils utilisent la base CDDB de Grancenote, mais je ne sais dans
quelle mesure cet usage est appliqué à Genius
3
Il est même possible d’affirmer que si vous écoutez les Beatles,
vous en céoutez aussi les membres au même moment… Mais n’allons
pas trop vite.
4Je
vais ici référence à la véritable pratique scientifique de
traitement automatique du langage naturel
Michelle Chanonat 20181224 – La revue JEU a décidé d’adopter la rédaction épicène, que ce soit pour les articles de la revue ou le site Internet. Grâce à ces quelques règles, et avec un peu de bonne volonté, la féminisation des textes devient possible. La langue est le reflet d’une société et elle doit évoluer avec elle. Ce guide de rédaction est évolutif. N’hésitez pas à l’enrichir et à le partager !
Définitions
Épicène :
vient d’un mot grec qui signifie « possédé en commun ».
Il décrit une technique de rédaction ou un
texte qui met en évidence, de façon équitable, la présence des
femmes et des hommes. Cette présence se manifeste par l’emploi de
mots qui désignent aussi bien les femmes que les hommes
(c’est-à-dire, par des formulations neutres), ou encore qui parlent
explicitement tantôt des femmes, tantôt des hommes (c’est-à-dire,
par la féminisation syntaxique).
Féminisation
lexicale : Procédé par lequel un nom ou un titre
masculin est transposé au féminin. Le rédacteur
devient ainsi la rédactrice,
l’agent financier supérieur devient
l’agente financière supérieure,
etc.
Féminisation
syntaxique : Procédé de rédaction par lequel on
nomme explicitement les femmes et les hommes, notamment par
l’utilisation de doublets dans les phrases (p. ex. : Le
gouvernement souhaite consulter les citoyennes et citoyens).
Générique :
Se dit d’un mot qui désigne une classe d’êtres ou d’objets
susceptibles d’être désignés chacun par un nom spécifique, p. ex.
: un cours d’eau (rivière, fleuve,
etc.) ou une personne (homme ou
femme).
Genre :
Le mot renvoie à deux notions distinctes : la catégorie
grammaticale d’un nom (féminin ou masculin); et le « sexe
social » d’une personne, par opposition à son sexe biologique.
1-
Employer le collectif
Les
noms collectifs désignent un ensemble de personnes, hommes ou
femmes. Même si ce procédé est accusé de faire « disparaître
les femmes », il peut être utile pour alléger un texte, mais
seulement de façon occasionnelle.
Les
titres de fonction ou noms d’unité administrative sont également
des termes collectifs. Il s’agit de termes qui désignent la
fonction qu’occupe une personne plutôt que son titre. On peut
également faire référence à l’unité administrative à laquelle
la personne est rattachée.
Exemples
:
Au
lieu de : « Ce prix est remis aux employés. »
Dire :
« Ce prix est remis au personnel. »
Au
lieu de : « Merci d’envoyer un courriel à la directrice. »
Dire :
« Merci d’envoyer un courriel à la direction. »
2-
Faire preuve de créativité et reformuler
Cela
permet de rédiger des textes inclusifs et harmonieux qui ne sont pas
interrompus par la répétition de la forme masculine et féminine
des substantifs et adjectifs.
Au
lieu de : « Êtes-vous citoyen canadien ou citoyenne
canadienne ? »
Dire :
« Avez-vous la nationalité canadienne ? »
3-
Avoir recours aux pronoms, termes, et adjectifs épicènes
Les
éléments épicènes ne sont pas marqués du point de vue du genre
grammatical, ils ont la même forme au masculin et au féminin. Ils
éliminent l’utilisation de doublets, et peuvent contribuer à une
plus grande concision et lisibilité.
Pronoms
épicènes : on, vous, quiconque, personne,
plusieurs, chaque…
Les
doublets peuvent être utilisés pour inclure les formes masculines
et féminines. Il faut cependant y avoir recours de manière
judicieuse, car la répétition continuelle des doublets tout au long
d’un texte risque d’entraver la lisibilité et l’intelligibilité
du contenu. Par ailleurs, il faut noter que les doublets incluent les
genres masculin et féminin, mais ne tiennent pas compte des
personnes qui se considèrent non conformes au genre.
Exemple :
cette politique s’applique à l’ensemble des travailleurs
et travailleuses.
5-
Les titres des postes, fonctions, métiers et grades au féminin
Utiliser
les formes féminines admises et attestées par les dictionnaires, y
compris celles qui sont combattues (autrice, écrivaine, professeuse,
régisseuse, metteuse en scène…) Ces mots ont des siècles
d’existence, ils peuvent donc être utilisés sans problème, même
si l’usage voulait qu’ils se rapportent à l’ÉPOUSE de,
comme : ambassadrice, générale, etc. Mais, depuis 1944, les
femmes sont susceptibles d’occuper toutes les fonctions.
Éviter
d’employer des féminins qui sonnent à l’oral comme des
masculins : professeure, proviseure, ou même chercheure (alors
que les chercheuses existent depuis longtemps). Si on dit danseuse ou
directrice, on peut dire commandeuse ou autrice.
Utiliser
les termes épicènes avec un article féminin : la ministre, la
journaliste, et accorder les adjectifs et participes qui s’y
rapportent : la secrétaire générale.
6-
Adopter l’accord de proximité
Exit
la règle qui dit que le masculin l’emporte sur le féminin !
L’accord de proximité, qui existe en latin et dans les langues
romanes, donne au dernier terme l’avantage d’indiquer l’accord,
ce qui nous fait dire : les hommes et les femmes sont belles.
Mais rien n’empêche d’écrire non plus : les femmes et les
hommes sont beaux…
L’accord
de proximité ne porte pas seulement sur les adjectifs, mais aussi
sur les verbes : « les corridors et les chambres
attenantes ont été aménagées,
elles permettent d’accueillir…»
7-
Le point médian
Le
petit point médian, très gracieux, a le mérite de donner à lire
la forme féminine, parce que l’œil la voit : musicien·nes
surdoué·es, écrivain·es entêté·es, avocat·es incompétent·es.
C’est le meilleur choix pour la féminisation de la langue, parce
qu’il est réservé à cet usage. On évite les parenthèses, les
barres obliques et autres signes, parce qu’ils « contribuent
à mettre les femmes entre parenthèses et n’habituent pas à voir
la forme féminine du mot1».
Le
point médian doit rester unique en
cas de pluriel : physicien·nes convaincu·es et non pas (comme
on le voit souvent) physicien·ne·s convaincu·e·s.
Il
faut également éviter d’employer le point médian lorsque les
deux formes sont distinctes : directeur·trice (ou pire :
directeur·rice – je le dis parce que je l’ai vu), car le mot
féminin apparaît comme disloqué. Il faut donc, dans ce cas,
utiliser les deux termes.
Comment
faire le point médian ?
Sur
GNU/Linux :
AltGr + ⇧
Maj + ; :
oss / français (variante), oss_latin9 / français (variante,
Latin-9 uniquement), mac / français (Macintosh), oss_nodeadkeys /
français (variante, sans touche morte), oss_sundeadkeys / français
(variante, touches mortes Sun)
AltGr + ⇧
Maj + 1 :
latin9 / français (variante obsolète), latin9_nodeadkeys /
français (variante obsolète, sans touche morte),
latin9_sundeadkeys / français (variante obsolète, touche morte
Sun)
AltGr + : :
français, français (sans touche morte), français (touches mortes
Sun), belge
⇧ Maj + AltGr + . :
bepo / français (Bépo, ergonomique, façon Dvorak), bepo_latin9 /
français (Bépo, ergonomique, façon Dvorak, Latin-9 uniquement),
⇧ Maj + *
(du pavé numérique) : oss / français (variante), bre /
français (breton), oss_nodeadkey / français (variante, sans touche
morte), oss_sundeadkeys / français (variante, touches mortes Sun)